Reinforcement fine-tuning (RFT), a two-stage framework consisting of supervised fine-tuning (SFT) and reinforcement learning (RL) has shown promising results on improving reasoning ability of large language models (LLMs). Yet extending RFT to large video language models (LVLMs) remains challenging. We propose VIDEOP2R, a novel process-aware video RFT framework that enhances video reasoning by modeling perception and reasoning as distinct processes. In the SFT stage, we develop a three-step pipeline to generate VIDEOP2R-CoT-162K, a high-quality, process-aware chain-of-thought (CoT) dataset for perception and reasoning. In the RL stage, we introduce a novel process-aware group relative policy optimization (PA-GRPO) algorithm that supplies separate rewards for perception and reasoning. Extensive experiments show that VIDEOP2R achieves state-of-the-art (SotA) performance on six out of seven video reasoning and understanding benchmarks. Ablation studies further confirm the effectiveness of our process-aware modeling and PA-GRPO.
Models perception and reasoning as distinct processes with separate supervision signals.
High-quality process-aware chain-of-thought dataset built through a three-step generation pipeline with automatic verification.
Process-aware RL algorithm providing separate perception and reasoning rewards for fine-grained credit assignment.
Consistent 1.9%–9.1% accuracy gains over base models across seven diverse video benchmarks.
VIDEOP2R follows the standard RFT setup with a specific focus on modeling video reasoning into perception and reasoning as distinct processes.
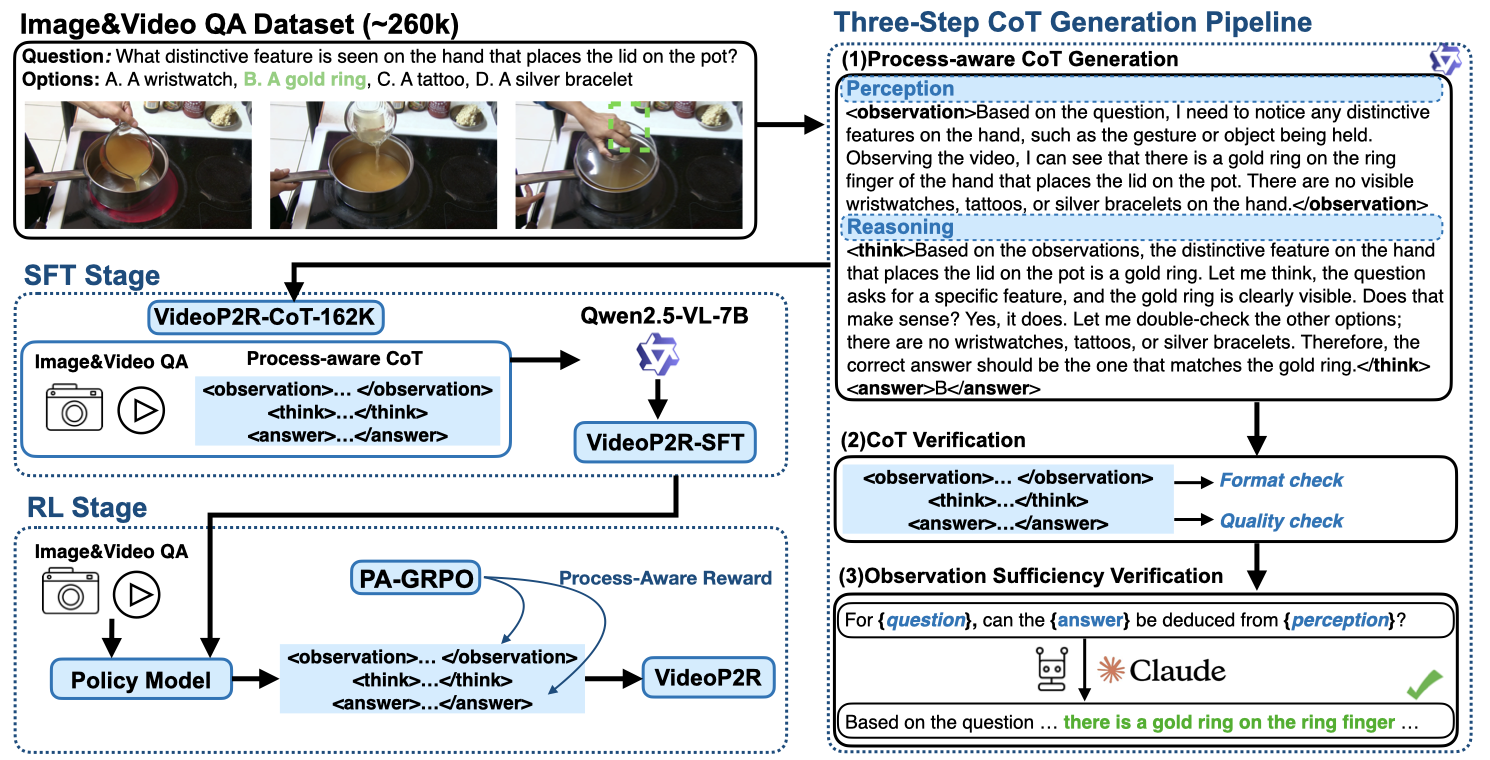
To address the lack of process-aware CoT data, we design a process-aware CoT template that explicitly disentangles perception from reasoning: <observation>...</observation> for extracting visual evidence, and <think>...</think><answer>...</answer> for reasoning and final answer. We then build a three-step pipeline to generate high-quality annotations at scale.
For each VQA sample, Qwen2.5-VL-72B-Instruct generates an initial CoT trace with explicit <observation> and <think><answer> segments following our process-aware template.
We evaluate each generated response with task-specific metrics (exact match, word error rate, ROUGE), discarding samples with low-quality answers or template deviations.
Claude 3.7 Sonnet validates the <observation> in a text-only setting, assessing whether the visual evidence is sufficient to support the correct answer without the raw video.
Applying the pipeline on 260K VQA data produces VIDEOP2R-CoT-162K — 162K high-quality process-aware CoT samples with perception and reasoning traces for SFT warm-up.
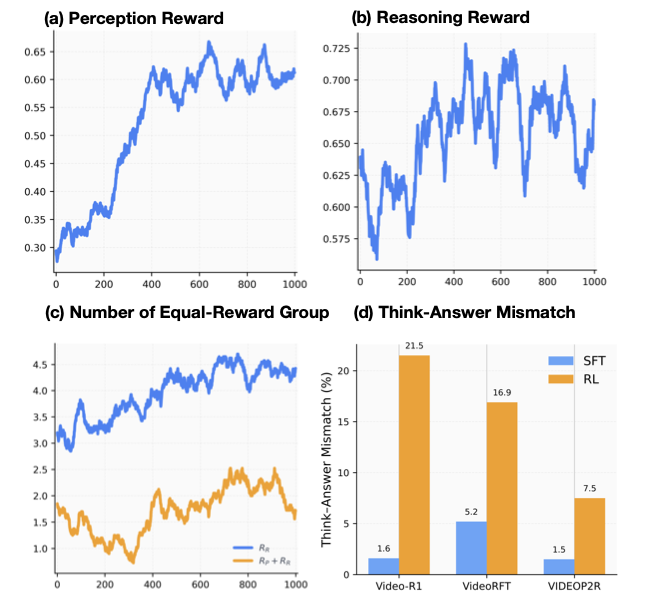
Standard GRPO assigns a single scalar reward to the entire trajectory, blurring credit assignment between perception and reasoning. PA-GRPO provides separate rewards for each process and normalizes them independently, enabling fine-grained credit assignment during RL.
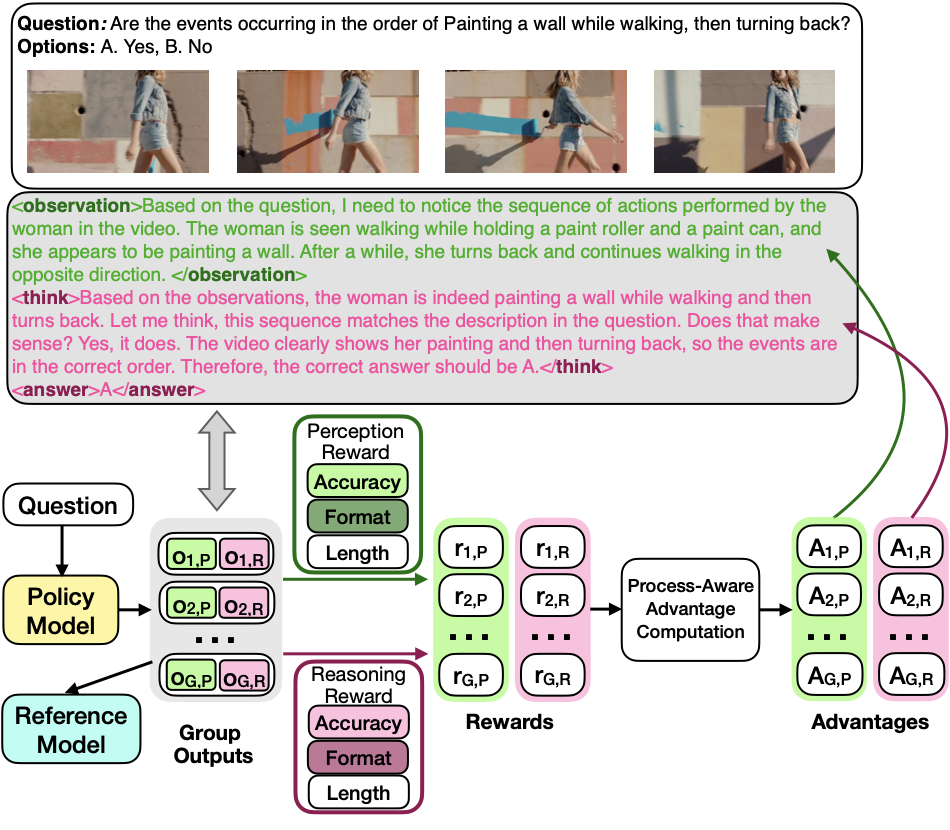
LLM-as-Judge evaluation: Claude 3.7 Sonnet assesses whether the <observation> segment contains sufficient visual evidence to support the correct answer in a text-only setting.
Task-specific rule-based evaluation: exact word match for categorical tasks, ROUGE-based similarity for open-ended QA, and error-based scores for numerical problems.
Separate format rewards enforce template adherence for each process. Length rewards favor concise yet informative outputs within target ranges (128–320 tokens for perception, 320–512 for reasoning).
SotA performance on 6 out of 7 video reasoning and understanding benchmarks
| Model | Video Reasoning | Video Understanding | Avg | |||||
|---|---|---|---|---|---|---|---|---|
| VSI. | VideoMMMU | MMVU | VCR. | MV. | TempCom. | VideoMME | ||
| Open-Source 7B Models | ||||||||
| LLaVA-OneVision-7B | 32.4 | 33.8 | 49.2 | — | 56.7 | — | 58.2 | — |
| LongVA-7B | 29.2 | 23.9 | — | — | — | 56.9 | 52.6 | — |
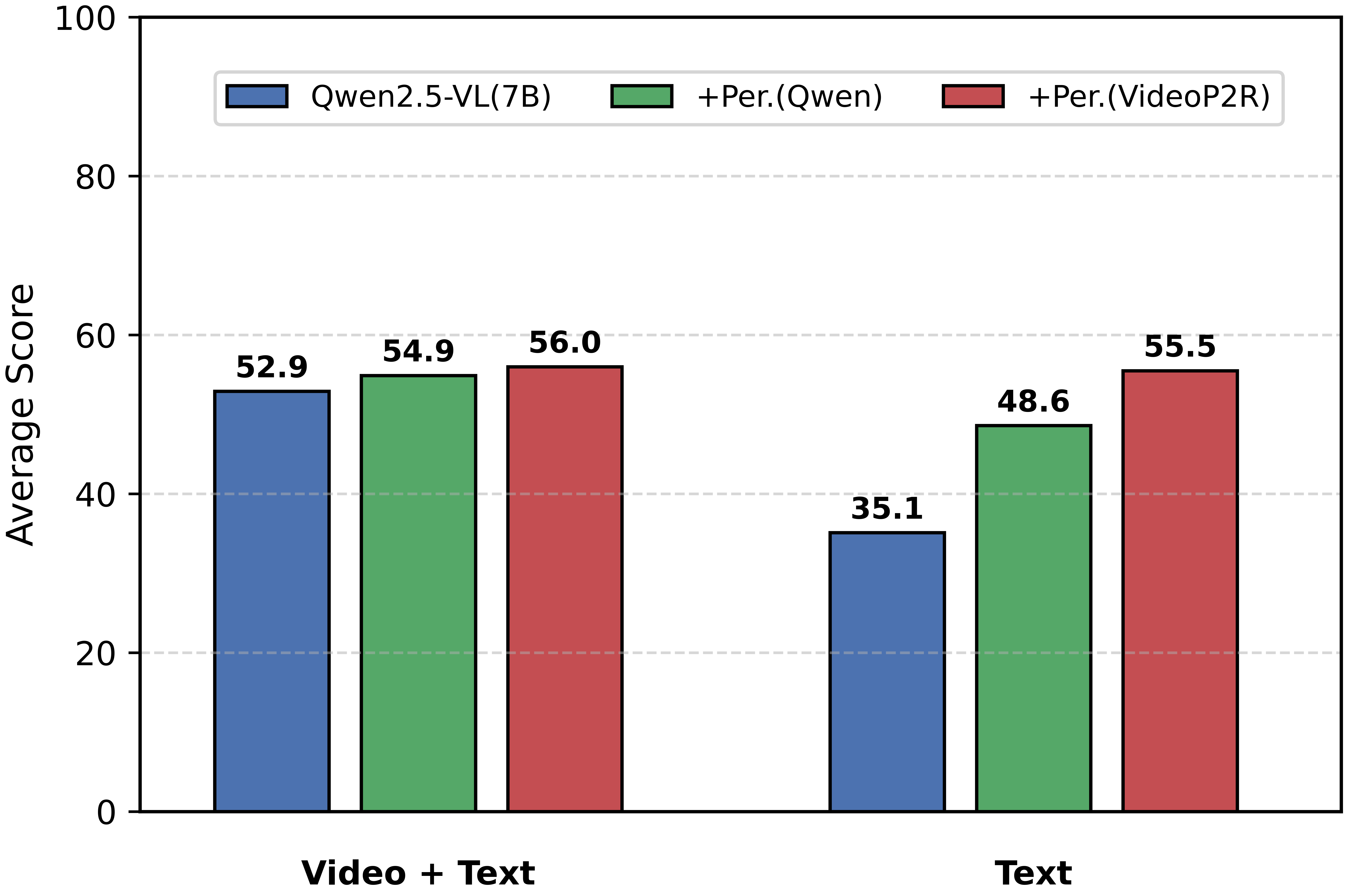
| Qwen2.5-VL-7B | 30.1 | 48.1 | 60.0 | 44.3 | 59.0 | 72.6 | 56.6 | 52.9 |
| RFT on Qwen2.5-VL-7B | ||||||||
| Video-R1 | 35.8 | 52.3 | 63.8 | 49.0 | 63.9 | 73.2 | 59.3 | 56.8 |
| VideoChat-R1 | 33.9 | 54.0 | 63.0 | 49.0 | 67.9 | 72.5 | 57.7 | 56.9 |
| Time-R1 | 29.0 | 51.0 | 62.9 | 49.6 | 63.1 | 73.7 | 59.3 | 55.5 |
| VersaVid-R1 | 33.7 | 51.9 | 64.3 | 49.8 | 62.9 | 74.0 | 58.8 | 56.5 |
| VideoRFT | 36.8 | 51.1 | 68.5 | 49.6 | 62.1 | 73.7 | 59.8 | 57.4 |
| VIDEOP2R (Ours) | 36.8 | 55.0 | 65.4 | 51.0 | 68.1 | 74.5 | 60.0 | 58.7 |
Best result in bold purple, second best underlined. All numbers in %.
Validating the contribution of each process-aware component
| Model Variant | Video Reasoning | Video Understanding | Avg | |||||
|---|---|---|---|---|---|---|---|---|
| VSI. | VideoMMMU | MMVU | VCR. | MV. | TempCom. | VideoMME | ||
| Two-stage Training | ||||||||
| VIDEOP2R (Ours) | 36.8 | 55.0 | 65.4 | 51.0 | 68.1 | 74.5 | 60.0 | 58.7 +5.8 |
| - SFT-only | 35.2 | 53.7 | 61.6 | 46.9 | 62.3 | 72.4 | 57.2 | 55.6 +2.7 |
| - RL-only | 35.8 | 54.6 | 64.6 | 46.3 | 60.8 | 73.8 | 55.9 | 56.0 +3.1 |
| Process-aware Modeling | ||||||||
| VIDEOP2R (Ours) | 36.8 | 55.0 | 65.4 | 51.0 | 68.1 | 74.5 | 60.0 | 58.7 +5.8 |
| - process-agnostic RL (GRPO) | 37.4 | 53.6 | 62.8 | 48.3 | 63.8 | 73.3 | 55.4 | 56.4 +3.5 |
| - process-agnostic SFT (no RL) | 34.3 | 48.9 | 61.6 | 47.3 | 59.0 | 69.7 | 54.0 | 53.5 +0.6 |
| Reward Design | ||||||||
| VIDEOP2R (Ours) | 36.8 | 55.0 | 65.4 | 51.0 | 68.1 | 74.5 | 60.0 | 58.7 +5.8 |
| - without RR | 36.0 | 51.6 | 60.3 | 46.8 | 62.1 | 72.5 | 57.9 | 55.3 +2.4 |
| - without RP | 37.4 | 53.6 | 62.8 | 48.3 | 63.8 | 73.3 | 55.4 | 56.4 +3.5 |
| - without RL | 40.0 | 52.7 | 63.2 | 48.4 | 65.5 | 73.9 | 60.0 | 57.7 +4.8 |
| - without separation | 37.1 | 53.2 | 64.9 | 48.8 | 65.0 | 73.2 | 59.7 | 57.4 +4.5 |
| Baseline: Qwen2.5-VL-7B | 30.1 | 48.1 | 60.0 | 44.3 | 59.0 | 72.6 | 56.6 | 52.9 |
Understanding why process-aware modeling works